|
Dan Cher I'm a PhD student at Washington University in Computational Data Sciences, where I have the honor of being an AI-ACCESS and Olin Chancellor's fellow. I'm working in the Multimodal Vision Research Laboratory led by Dr. Nathan Jacobs. Prior to the PhD, I worked as a Data Scientist (6 YoE) tackling geospatial problems focusing on using machine learning to quantify the risk of where people live and drive. Also built some aerial imagery models. During that time I received my MS in Data Science from Worcester Polytechnic Institute. |

|
ResearchI am interested in computer vision, multi-modal modeling and its applications to geospatial problems. My work has focused on satellite image synthesis and multimodal representation learning for geospatial and ecological problems. |

|
Tessellating the Earth: Learnable Spherical Voronoi Partitions for Location Encoding
Dan Cher, Hamza Iqbal, Eric Xing, Brian Wei, Nathan Jacobs ECCV, 2026 Project Page arXiv · soon Code · soon A location encoder that replaces fixed bases (e.g., spherical harmonics) with a learnable Spherical Voronoi partition of the sphere, concentrating capacity where the world is complex; global semantic tokens share concepts across distant sites. New state of the art for location encoders. |

|
TerraDiT-Ω: Unified Spatial Control for Satellite Image Synthesis with Any Geospatial Primitive
Brian Wei*, Srikumar Sastry*, Dan Cher*, Eric Xing, Nathan Jacobs ECCV, 2026 Project Page Code arXiv · soon Generalizes point-conditioned control to any geospatial primitive — points, bounding boxes, polylines, and polygons — through Geometry-Aware Local Attention (GALA). |

|
TerraDiT: Point-Conditioned Diffusion Transformer for Satellite Image Synthesis
Srikumar Sastry*, Dan Cher*, Brian Wei*, Aayush Dhakal, Subash Khanal, Dev Gupta, Nathan Jacobs arXiv, 2026 arXiv Code Generates satellite imagery conditioned on point queries — spatial points paired with textual descriptions — enabling precise, annotation-efficient control without dense maps. |

|
VectorSynth: Fine-Grained Satellite Image Synthesis with Structured Semantics
Dan Cher*, Brian Wei*, Srikumar Sastry, Nathan Jacobs WACV, 2026 Project Page Code arXiv We introduce VectorSynth, a diffusion-based model that generates pixel-accurate satellite imagery from polygonal geographic annotations with semantic attributes, enabling spatially grounded, geometry- and language-guided image synthesis and editing with superior semantic and structural fidelity. |
|
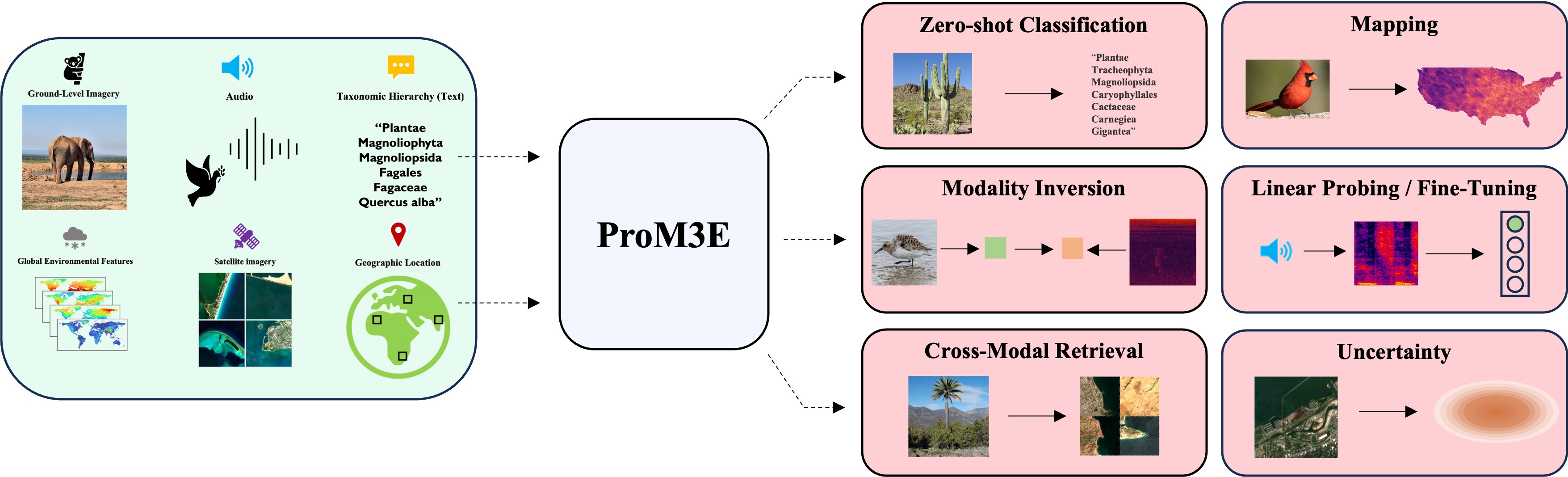
ProM3E: Probabilistic Masked MultiModal Embedding Model for Ecology
Srikumar Sastry, Subash Khanal, Aayush Dhakal, Jiayu Lin, Dan Cher, Phoenix Jarosz, Nathan Jacobs CVPR, 2026 arXiv We introduce ProM3E, a probabilistic masked multimodal embedding model that enables any-to-any modality generation, fusion feasibility analysis, and superior cross-modal retrieval and representation learning through masked modality reconstruction in the embedding space. |